
A Inteligência Artificial (AI) está transformando a forma como interagimos com a tecnologia, desde assistentes virtuais até sistemas de análise de dados. Um dos desafios ao trabalhar com modelos de linguagem é executá-los de forma local, sem depender de servidores externos, até por questões de segurança como compartilhar dados com terceiros. Nesse artigo usaremos o ollama
O Ollama é uma ferramenta poderosa para rodar modelos de linguagem de forma autônoma e ao utilizá-lo em Docker, você simplifica a instalação, garante isolamento de ambientes e facilita a portabilidade.
Neste artigo, exploraremos como usar o Ollama em Docker e iremos brincar um pouco com a IA de forma rápida, prática e eficiente.
📜 O que é a Inteligência Artificial (AI e IA)?
A Inteligência Artificial (conhecida com as abreviações AI e/ou IA) refere-se à capacidade de máquinas de realizar tarefas que normalmente exigem inteligência humana, como reconhecer padrões, tomar decisões, gerar texto, imagens ou videos. Modelos de linguagem, como os da família LLaMA, são exemplos de IA que aprendem com grandes volumes de dados para prever palavras, responder perguntas, escrever artigos e entre outras tarefas que podem nos ajudar no dia a dia
🚀 Por que usar o Ollama em Docker?
O Ollama permite rodar modelos de linguagem localmente, sem depender de APIs externas. Ao usar o Docker, você:
- Isola o ambiente de execução do Ollama, evitando conflitos com outros softwares.
- Facilita a portabilidade, pois o contêiner pode ser executado em qualquer sistema com Docker instalado.
- Simplifica a instalação, pois não é necessário configurar dependências complexas.
📋 Antes de começar, se você ainda não instalou o Docker, confira nossos tutoriais anteriores sobre como configurar o Docker no Linux.
🛠️ Pré-requisito: Instalando o Nvidia Container Toolkit
O NVIDIA Container Toolkit inclui o NVIDIA Container Runtime e o plugin NVIDIA Container Toolkit para Docker, que permitem suporte a GPU dentro de contêineres Docker.
Antes da instalação, certifique-se de que você já instalou os drivers da GPU na sua distribuição específica.
Agora, para instalar o NVIDIA Container Toolkit, siga estas etapas:
- Habilite o repositório NVIDIA CUDA no seu sistema executando os seguintes comandos em uma janela de terminal:
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list sudo apt update
- Instale o NVIDIA Container Toolkit executando o seguinte comando em uma janela de terminal e então reinicie o docker
apt update apt-get install -y nvidia-container-toolkit nvidia-ctk runtime configure --runtime=docker systemctl restart docker
- Verifique se o docker consegue enchergar a GPU:
docker run --rm --runtime=nvidia --gpus all ubuntu nvidia-smi
Com o comando acima devemos ver algo parecido como:
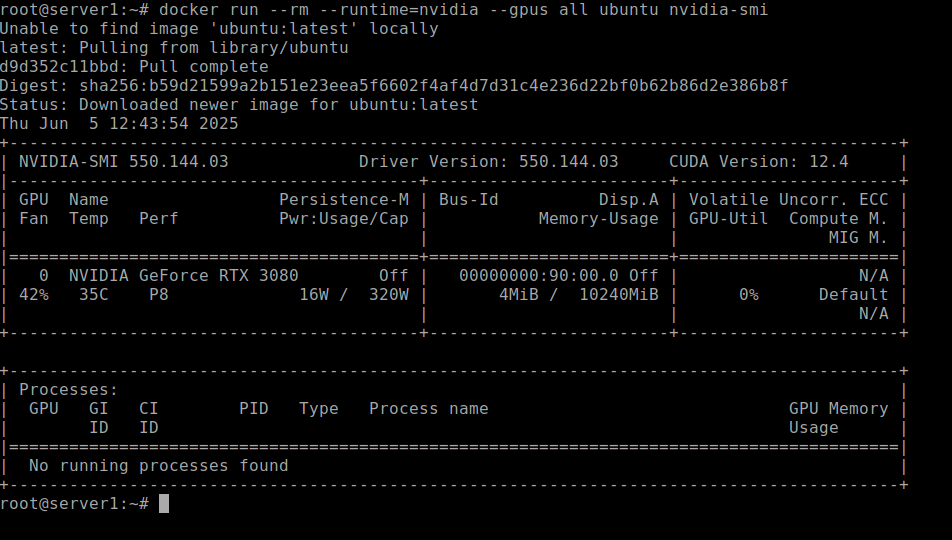
Se tudo ocorreu conforme imagem, então teremos uma performace maior utilizando a GPU para processamento dos modelos de IA. Também é possivel usar o processador, porém a performance será muito baixa. O ideal é utilizarmos uma GPU!
📌 Passo a Passo para Instalar e Usar o Ollama em Docker
- Instale o Docker
Se você ainda não tem o Docker instalado, siga as instruções do site oficial .
Método 1: Executando Ollama com Docker run (Método rápido)
Se você quer apenas criar o Ollama em um contêiner sem muita complicação, este simples comando resolverá o problema:
docker run -d --name ollama -p 11434:11434 -v ollama:/root/.ollama ollama/ollama
Ou, se você quiser suporte à GPU:
docker run -d --gpus=all -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
Aqui está uma análise do que está acontecendo com este comando:
docker run -d: Executa o contêiner no modo desanexado.--name ollama: Nomeia o contêiner como “ollama”.-p 11434:11434: Mapeia a porta 11434 do contêiner para o host.-v ollama:/root/.ollama: Cria um volume persistente para armazenar modelos.ollama/ollama: Usa a imagem oficial do Ollama Docker.
Depois que o contêiner estiver em execução, você pode verificar seu status com:
docker ps
Método 2: Executando Ollama com Docker Compose
Usar o Docker Compose é uma abordagem mais estruturada ao configurar um serviço dentro de um conteiner, pois é muito mais fácil de gerenciar.
💡 Se você estiver configurando o Ollama com o Open WebUI, sugiro usardocker volumesao invez debind mountspara uma experiência menos frustrante.
Começaremos criando um arquivo docker-compose.yml para gerenciar o contêiner Ollama:
version: '3.8'
services:
ollama:
image: ollama/ollama
container_name: ollama
ports:
- "11434:11434"
volumes:
- ollama:/root/.ollama
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: all
capabilities: [gpu]
restart: unless-stopped
volumes:
ollama:
Com o arquivo docker-compose.yml dentro de um diretório vazio, inicie o contêiner usando o comando:
docker-compose up -d
Isso iniciará o Ollama com a aceleração de GPU habilitada.
🌐 Acessando Ollama no Docker
Agora que temos o Ollama em execução dentro de um contêiner Docker, podemos interagir com ele.
Existem duas maneiras:
1. Usando o shell do Docker
Isso é muito fácil, você pode acessar o shell do contêiner Ollama digitando:
docker exec -it ollama /bin/bash
vamos baixar nosso primeiro modelo pré treinado digitando o comando (depois de ter acessado o container / comando anterior):
ollama pull llama3
2. Usando a API do Ollama com clientes de interface de usuário da Web
O Ollama expõe uma API no http://localhost:11434, permitindo que outras ferramentas se conectem e interajam com ela.
Podemos usar o curl para realizar nossa primeira pergunta ao ollama:
curl -X POST http://localhost:11434/api/generate -d '{
"model": "llama3",
"prompt": "Explique o que é o Docker."
}'
Se você preferir uma interface gráfica de usuário (GUI) em vez da linha de comando, poderá usar vários clientes de interface de usuário da Web.
Algumas ferramentas populares que funcionam com o Ollama incluem:
- Open WebUI – Um frontend simples e bonito para LLMs locais.
- LibreChat – Uma interface poderosa semelhante ao ChatGPT com suporte a vários backends.
📌 Conclusão
Usar o Ollama em Docker é uma maneira eficiente de explorar a Inteligência Artificial de forma local e isolada. Com o Docker, você evita dependências externas e garante que o sistema execute de forma portável. Se quiser, você também pode integrar o Ollama com outros serviços ou ferramentas para automatizar workflows de IA.


